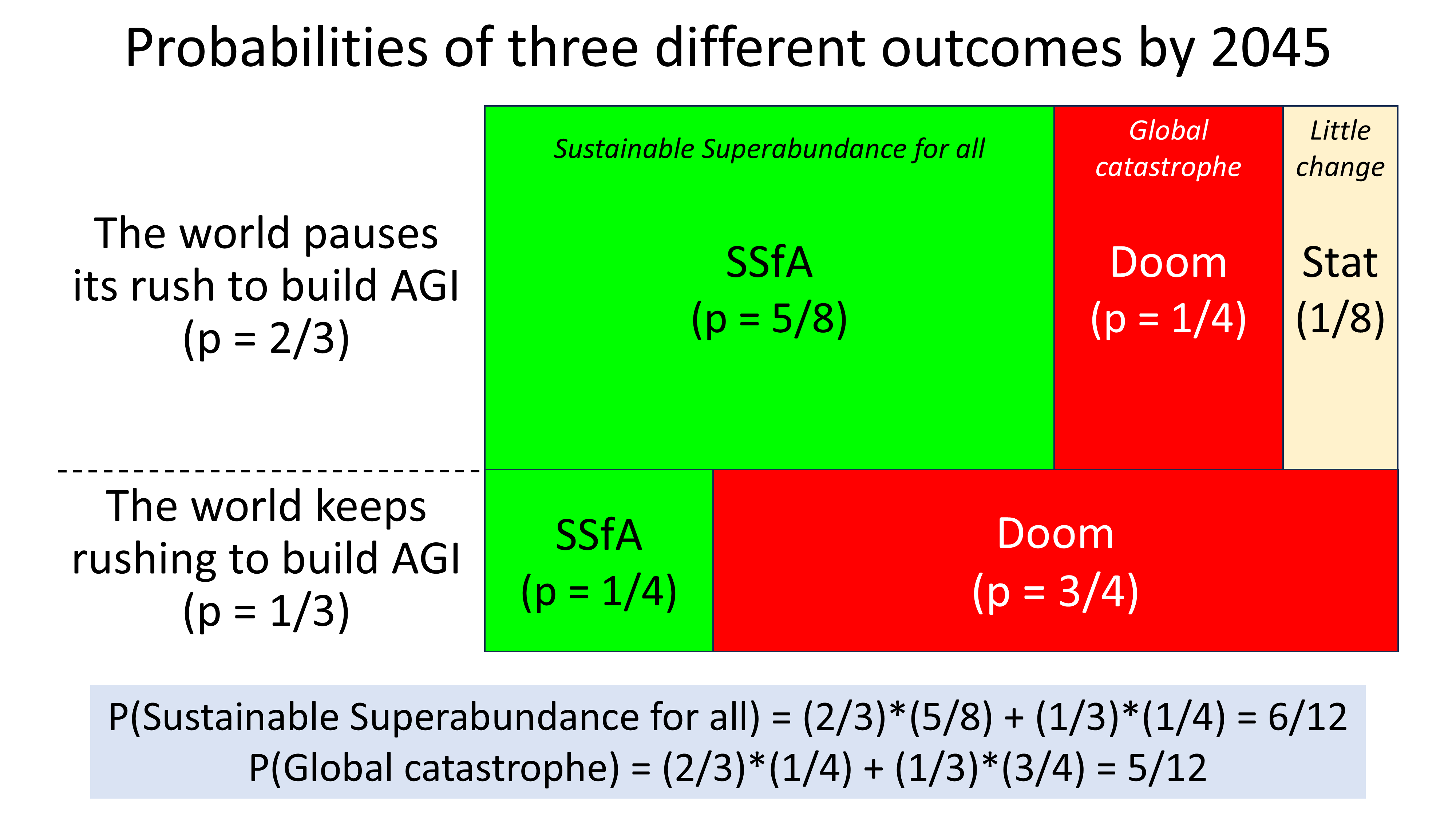
How can global society constrain the actions of its most dangerous elements – the elements which might act recklessly and destructively, whether out of naivety or out of malice?
(Bear in mind that the adverse impact of reckless or dangerous action is being magnified by ever more powerful technology!)
How can these constraints be applied, judiciously, without imposing undue burdens on vital everyday activities?
How can innovation best be encouraged and supported, that will provide people everywhere with more choice, greater security, stronger freedoms, and deeper fulfilment?
How can people with multiple different interests and conflicting outlooks live cheek by jowl on a planet that is increasingly stressed, contested, complicated, and volatile?
These are questions of governance. In turn, they raise questions of who governs, with what remit, and under what oversight.
These are all good questions, but answers are far from clear.

A major complication is that traditional answers to the “who governs” question have fallen into disrepute. Elected politicians, nominated experts, market forces, vocal public opinion, self-declared strongmen, assertive theocrats, and advanced information technology systems – all of these have large question marks regarding their reliability and trustworthiness. And when people do come together, to try to bridge the wide gulfs that often separate them, the process is usually slow and frustrating.
In consequence, governance is proving increasingly ineffective and counterproductive – at a time where good global governance is especially needed:
- Emerging technologies are magnifying the scale, speed, and concentration of power.
- As a result, weaknesses in governance that were once tolerable are becoming increasingly dangerous.
To move things forward, I seek to identify a core set of commitments that might be adopted near universally – by people in all walks of life, from different cultural backgrounds, with diverse political outlooks, and with numerous opposing instincts and beliefs. These shared commitments will, if fit for purpose, provide the framework for better lives for everyone.
That may seem a hopelessly naïve aspiration. The risk is that any agreement which can command wide assent will consist of vague lowest common denominator principles, open to multiple divergent interpretations. Slogans like “Give peace a chance”, “Live and let live”, “All you need is love”, “Be fair to everyone”, and “Trust the science” leave a great deal unsaid – such as how to cope with entities that prefer war to peace, how to address harms imposed on third parties, how to adjudicate between different concepts of fairness, and what to do when scientists disagree among themselves.
Nevertheless, I offer the principles in this article – design commitments for trustworthy technoprogressive governance – as principles that could have real teeth.
I offer them not just as a set of commitments that I personally aim to embody. Instead, I offer them as a candidate set of principles that could, in stages, build increasingly global consensus. By being adopted in ever larger circles, these commitments could inspire growing numbers of people to prioritise their actions in ways that will significantly boost constructive coexistence and overall flourishing.
These commitments are intended neither as legislation nor as a complete political programme. Rather, they are proposed as a design checklist against which institutions, technologies, policies, and governance arrangements can be evaluated.
Introducing the commitments
My view is that constructive coexistence will become much easier with three kinds of shared commitments that can span the many differences that will still exist between people:
- Some shared ethical commitments about whose interests matter and what kinds of outcomes are unacceptable
- Some shared epistemic commitments about evidence, uncertainty, prediction, and correction
- Some shared governance commitments about accountability, concentrated power, and reversibility.
I therefore present three categories of principle:
- A: Moral standing and flourishing
- B: Epistemic integrity
- C: Power, governance, and risk.
I precede these with two foundational premises – on the central importance, respectively, of technology, and of social structure.
I don’t expect this set of design commitments to be adopted in the precise form I present them here. The list will surely need to pass through many revisions and improvements first. But I share them with the hope they will be seen as a useful starting point for a wider conversation.
I welcome feedback. (See the Endnote for suggestions on the kind of feedback to prioritise.)
Note: These principles are derived from a previous essay of mine, which reviews many background considerations: “Building a Spiral of Trust for Emerging Technologies”.

F. The foundational premises
The first foundational premise emphasises that technology matters – especially changes in technology. The second emphasises – in contrast to views which focus on the actions of individuals – that society matters.
The first premise highlights that technology expands what is possible; the second that institutions determine what becomes achievable safely, fairly, and beneficially.
These two premises reflect, respectively, the first and second parts of the word technoprogressive.
Taken together, these two premises clarify that the central challenge of technoprogressive governance is to ensure that our collective capacity for coordination keeps pace with our expanding technological capabilities.
F1. Pay serious attention to the profound transformative potential of emerging technologies
Technologies of many kinds have already deeply transformed the human condition, but forthcoming emerging technologies could take matters much further – with consequences that could be either profoundly beneficial or deeply detrimental.
Technologies differ not only in what they enable directly, but also in how they reshape the landscape of future possibilities. While many technologies primarily improve existing activities, others eventually reshape the capabilities of entire societies, creating enormous opportunities, profound vulnerabilities, and dramatic redistributions of power. These wider indirect effects can ultimately matter far more than the immediate applications of the technology itself.
Decisions about technology therefore need to consider not only the impacts of current technologies but also the potentially significantly larger impacts of emerging technologies, including new generations of AI, robotics, nanotech, biotech, and cognotech.
Note: This principle is entirely compatible with also recognising the very considerable exaggerations and hyping of many technological products.
Expanding technological capability without corresponding advances in our ability to coordinate its use increases not only humanity’s opportunities but also its exposure to catastrophic failure. That takes us to the next fundamental premise.
F2. Recognise the deep social factors behind flourishing: culture, institutions, worldviews…
The human condition depends not just on technologies but on the health and vitality of our society – culture, institutions, and worldviews. This includes markets, knowledge sharing, financial infrastructure, legal systems, independent enquiry, media exchange, governance protocols, behavioural norms, interpersonal expectations, how power is divided and distributed, and shared beliefs about matters such as metaphysics, virtues, responsibility, and purpose.
One of the central functions of these social structures is to sustain cooperation among people who do not know, trust, or even like one another. Markets, legal systems, scientific norms, democratic procedures, and reputational mechanisms all help societies reap the benefits of large-scale cooperation while limiting the damage caused by fraud, exploitation, and other forms of defection. As technologies increase the scale and speed of both cooperation and defection from cooperative norms, these institutions become correspondingly more important.
When these social factors operate badly, they are oppressive, restrictive, and divisive. But when they work well, they are empowering, liberating, and unifying
In simple terms, consider the saying “it takes a village to raise a child”. In broader terms, we are all highly dependent on what each other do.
Social structures influence not only the degree of flourishing at the present time, but also the ways in which flourishing might increase (or diminish) in the future. Structures which were well suited to earlier times, with one set of technologies dominant, may prove badly suited to later times. Hence the importance of being willing to reform these structures, without dismantling them before understanding the valuable functions they perform.
An important complication: Governance itself must evolve
The effectiveness of governance institutions depends not only on their constitutional design but also on the material conditions that sustain them. Stable tax bases, productive economies, widely distributed bargaining power, civic participation, and the availability of independent expertise all contribute to society’s capacity to enforce norms, maintain accountability, and constrain concentrations of power. These foundations should not be assumed to remain unchanged as technology transforms economic relationships.
Given the possibility that emerging technologies could substantially reduce the economic leverage of large sections of the population – or otherwise reshape the material foundations on which accountable governance has historically depended – it is a matter of considerable urgency that governance institutions evolve before power moves irreversibly into narrower hands.
A. Moral standing and flourishing
The principles in this group address whose interests matter and how technological progress should support human and wider flourishing.
A1. Direct technological progress toward sustainable flourishing
Technological development should not be treated as an end in itself. Before asking whether a technology can be built, we should ask what purposes it serves.
Decisions about research, investment, development, and deployment should consider which forms of flourishing a technology is intended to enable, whose interests it advances, what alternative purposes and opportunities it may displace, what alternative methods exist to meet the desired goals, whether those purposes remain worthy under changing circumstances, and whether the direction of development remains open to challenge and revision.
No single conception of flourishing should simply be imposed on everyone. The aim should be to expand people’s opportunities for diverse forms of flourishing, consistently with equal moral standing, meaningful agency, sustainability, and appropriate protection against severe harms imposed on others.
A2. Protect the option of continued life
Anyone who wishes to continue living should, as far as reasonably achievable, be protected from involuntary death and enabled to benefit from technologies that preserve and restore health.
Specifically, even if someone is disabled or in a state of chronic ill-health, they should face no threat of involuntary death. They should be enabled to benefit from advances that preserve life, restore health, boost vitality, overcome disability where desired, and progressively reduce the burden of disease and aging.
A3. Treat no group as expendable
Technological progress should not be purchased by treating particular populations as disposable collateral damage, or by imposing severe avoidable harms on them merely because they lack political, economic, or social power.
Major technological decisions should explicitly identify which groups bear the risks, costs, and disruptions of proposed changes, and should not systematically concentrate severe harms on populations that lack effective political, economic, or social representation.
Regrettable past historical episodes should be borne in mind, to avoid similar instances.
Claims that harms are justified by aggregate benefits should face particularly strong scrutiny when those harms fall disproportionately on vulnerable groups.
A4. Share the gains of technological progress broadly
Those who contribute capital or ingenuity may deserve special rewards, but transformative technologies should not create permanent castes of winners and losers.
New capabilities in health, education, communication, intelligence amplification, and economic opportunity should not remain indefinitely restricted to small privileged groups when broader access is technically and economically achievable.
Institutions should therefore be assessed not only by the wealth they create, but also by how widely people can participate in, benefit from, and adapt to the opportunities created.
A5. Recognise equal moral standing without requiring identical treatment
Every person’s fundamental interests deserve equal moral consideration, while recognising that fairness sometimes requires different treatment in different circumstances.
The interests of other sentient beings should also receive consideration proportionate to our confidence in their capacity for experience and suffering.
A6. Preserve meaningful human agency
People should retain meaningful ability to shape their own lives rather than being manipulated into nominally beneficial outcomes that other people decide on their behalf.
The objective should not merely be to maximise welfare as judged by external observers. People should retain meaningful opportunities to understand, influence, and participate in decisions that shape their lives.
A7. Respect pluralism in conceptions of flourishing
Different people and communities legitimately pursue different visions of a good life.
Future flourishing may take forms that differ substantially from contemporary expectations. People may choose different relationships to technology, enhancement, longevity, work, family, cognition, culture, or spirituality.
Governance arrangements should therefore avoid unnecessarily imposing a single comprehensive conception of fulfilment, success, virtue, spirituality, family structure, or life purpose. Instead, institutions should seek to create conditions under which diverse forms of flourishing can coexist, provided they respect the equal standing and agency of others.
B. Epistemic integrity
These principles describe how trustworthy knowledge should be generated.
B1. Reduce trust in sources of disinformation
Good decisions are much harder if people are being misled about facts, intentions, or capabilities.
If a source is guilty of deliberate deception, reckless disregard for evidence, or repeated dissemination of demonstrably false claims, this should reduce the degree of trust placed in their subsequent communications.
At the same time, safeguards should protect good-faith disagreement, uncertainty, and the correction of honest mistakes.
B2. Expose the assumptions behind decisions
Key decisions should make visible the factual assumptions, forecasts, value judgements, and uncertainty estimates on which they depend.
B3. Make conflicts of interest visible
People and institutions exercising influence over major technological decisions should disclose material financial, organisational, and personal interests that could reasonably affect their judgement, along with significant prior commitments that bear directly on the issue under consideration.
B4. Treat dissent as a resource
Well-informed disagreement should be protected and actively sought, especially when consensus may reflect conformity, intimidation, fashion, or shared blind spots.
B5. Protect whistleblowers
Anyone who becomes aware of a serious disconnect between claimed values and actual behaviour should have safe channels to report their concerns and should be protected against retaliation when raising them in good faith.
B6. Value relevant competence
Universal moral standing does not imply that every person has equal expertise on every question. Good decision-making should combine democratic legitimacy with relevant competence.
B7. Make predictions, observe outcomes, and update
Trust should depend not merely on confidence, but on demonstrated calibration: how well previous predictions corresponded with subsequent outcomes.
Accordingly, governance arrangements, policies, and technical systems should be monitored against explicit expectations stated in advance wherever possible. When outcomes diverge from predictions, institutions should investigate why, update their models, and change course where necessary.
Without this cycle of prediction, observation, and revision, discussions can lose touch with reality.
Collaborative information systems can provide significant help here by recording forecasts, tracking outcomes, and preserving an auditable history of updates.
B8. Design for human irrationality and motivated reasoning
Better information does not guarantee better decisions. People frequently interpret evidence through the lenses of identity, emotion, group loyalty, status, and prior commitment.
Trustworthy decision processes should therefore be designed to reduce predictable cognitive and social distortions – for example through structured disagreement, independent judgement before group discussion, protection against conformity pressures, and deliberate testing of propositions against evidence that could prove them wrong.
C. Power, governance, and risk
These principles address how power should be constrained, legitimacy sustained, and systemic risks managed.
C1. Hold power accountable
The greater the power exercised by a person, corporation, state, or technical system, the stronger the requirements for scrutiny, challenge, and correction.
C2. Anticipate that power will resist accountability
Governance arrangements should not assume that powerful actors will voluntarily accept constraints merely because those constraints are reasonable or socially beneficial. States, corporations, military establishments, wealthy individuals, and entrenched institutions may resist scrutiny, exploit loopholes, shape public narratives, or undermine reforms that threaten their interests.
Trustworthy governance therefore requires appropriate forms of countervailing power, enforceable constraints, independent scrutiny, and realistic attention to the incentives of actors who may prefer the status quo.
C3. Renew the foundations of accountable governance
Governance arrangements should not assume that the economic, technological, demographic, or social conditions that have historically sustained effective governance will persist indefinitely.
Where emerging changes could weaken accountability, legitimacy, expertise, civic participation, public revenues, or countervailing power, replacement or supplementary foundations should be developed while existing institutions still possess sufficient authority, resources, expertise, and public support to establish them.
Institutional renewal should therefore proceed before deteriorating governance capacity makes such renewal substantially harder or impossible.
Responsibility for this renewal cannot be assigned to “society” in the abstract. It must be allocated among identifiable institutions with the authority, resources, competence, and legitimacy to act, including governments, legislatures, civil society, organised labour, professional bodies, and new forms of public-interest institution.
Proposals should identify how the new arrangements will be funded, how their independence will be protected, and what powers or incentives will make them effective against resistance.
C4. Ensure procedural fairness
Trust depends not only on whether decisions produce good outcomes, but also on whether the processes leading to them are widely regarded as fair. People affected by important decisions should have appropriate opportunities to be heard, reasons should be given for consequential choices, comparable cases should be treated consistently, and mechanisms for challenge and appeal should be available. Technical competence without perceived legitimacy is unlikely to sustain public trust.
C5. Resist effectively irreversible concentrations of power
Emerging technologies can create unprecedented concentrations of capability and control. Arrangements that would become extremely difficult to challenge, reverse, or escape should face an exceptionally high burden of proof.
C6. Prefer corrigibility, reversibility, and contestability
Where uncertainty is high, prefer interventions that can be monitored, corrected, halted, or reversed.
Where feasible, governance arrangements should avoid unnecessary monopoly. When institutions become captured or ineffective, there should be scope for alternative analyses, institutions, and approaches to emerge, provided systemic risks and unavoidable externalities are appropriately managed.
C7. Apply precaution proportionately
Neither “move fast and break things” nor “ban anything uncertain”. The degree of caution should rise with the scale, irreversibility, and uncertainty of possible harm.
C8. Beware fat tails
Many familiar risk calculations implicitly assume that extreme outcomes are extraordinarily rare. But where systems contain strong interdependencies, feedback loops, or common-mode vulnerabilities, distributions can have “fat tails”: extreme events may be much more likely than extrapolation from ordinary fluctuations suggests.
In practical terms, this means any plans for the future should beware the creation of monocultures that lack sufficient diversity – cultures in which all the variations can move in the same direction at once. We should also beware the influence of hidden connections, such as the shadow links between multiple different financial institutions that precipitated the global financial crisis of 2008.
Emerging forms of AI-driven trading and financial automation may create additional risks of correlated behaviour, feedback loops, and instability operating faster than human supervisors can understand or interrupt. Financial innovation should therefore be assessed not only for the efficiency it creates in normal conditions, but for the systemic behaviour that can emerge under stress.
C9. Demand stronger evidence of safety for catastrophic risks
Where a plausible failure mode could cause irreversible civilisation-scale harm, ordinary standards of product testing and post-deployment correction are insufficient. The burden of demonstrating adequate safety should rise with the potential scale of catastrophe.
Note in particular that some particularly dangerous technologies – including biopathogens and misaligned AI – could escape into the wild even during a test phase inside a supposedly secure environment. In such cases, clear evidence of safety must be provided at the design phase, rather than after a test phase.
C10. Apply subsidiarity where possible and coordinate where necessary
Decisions should be taken close to the people affected – except where externalities, systemic risks, or global consequences require wider coordination.
C11. Preserve future freedom of choice
Avoid prematurely locking civilisation into institutions, technologies, values, or power structures that future people cannot escape.
C12. Preserve diversity among institutions and models
Coordination should not require unnecessary uniformity. Where feasible, societies should preserve multiple institutions, analytical approaches, technical architectures, and centres of expertise, so that errors in one do not automatically propagate throughout the whole system.
Diversity can create inefficiency and disagreement, but it can also provide resilience, experimentation, and protection against common-mode failure.
C13. Retain humanity’s ability to correct and constrain technology
At least until much stronger foundations of trust and control exist, high-stakes systems should remain subject to effective correction, constraint, and ultimately withdrawal of authority through accountable human institutions, rather than acquiring open-ended autonomous power to pursue goals in the world.
No system should acquire effectively irreversible authority over humanity merely because it is more intelligent, efficient, persuasive, or strategically capable than individual humans.
More generally: High-stakes systems should remain subject to effective correction and constraint through accountable human institutions. “Human control” is not enough if that control is itself concentrated in unaccountable hands.
Further challenges and open questions
A framework of governance commitments is incomplete unless it is accompanied by a credible account of the transition: who can build the required institutions, using which resources and powers, and before which existing capacities deteriorate.
The principles and processes outlined above are intended as starting points, not as a complete theory of governance for emerging technologies. Several major challenges require deeper analysis.
I present these challenges as open research questions. They don’t invalidate the framework, but they indicate where more attention is needed.
Q1. Political economy and entrenched power
A technically superior governance arrangement may fail if actors with sufficient power have strong incentives to block, capture, hollow it out, or simply ignore it.
This highlights two distinct challenges. The first is to design institutions that genuinely deserve trust. The second is to enable those institutions to acquire sufficient legitimacy, leverage, incentives, and enforcement capacity that the most powerful actors cannot simply opt out of them. These two challenges are related but not identical.
In particular, if deployment of transformative AI is driven by intense commercial competition, geopolitical rivalry, or military advantage, organisations with the greatest capabilities may have strong incentives simply to ignore governance arrangements that constrain them.
Hence the following require close attention:
- How can opponents of change become allies rather than spoilers?
- How can trustworthy institutions acquire sufficient influence before economic and political power shifts irreversibly elsewhere?
- How can countervailing power arise?
A further challenge concerns the material foundations of governance capacity itself. Historically, effective governance has depended upon economic arrangements that generated tax revenues, professional institutions, widespread participation, and forms of countervailing power. Emerging technologies may soon substantially alter these foundations. Which new economic and social arrangements could sustain effective governance under these changed conditions?
Q2. Detecting the narrowing window for institutional renewal
Principle B7 argues that important claims should be accompanied by expectations stated in advance so that later observations can confirm or disconfirm them. The urgency claim in this article should therefore be connected to observable indicators rather than resting solely on intuition.
Developing a robust set of such indicators should itself be regarded as an urgent research priority.
No single indicator will determine whether effective institutional renewal remains possible, but relevant warning signs may include:
- Sustained declines in entry-level recruitment across highly AI-exposed occupations
- Output or profit growth increasingly decoupled from employment and wage-bill growth
- Declining labour share of national income and bargaining power
- Public revenues becoming increasingly difficult to raise from the principal beneficiaries of technological change
- Growing concentration of ownership, computational resources, data, political influence, or research capacity
- Declining state capacity, regulatory staffing, independent expertise, or public confidence
- Increasing dependence of public institutions on funding from the actors they are expected to govern.
These indicators should be monitored across jurisdictions, with forecasts and thresholds stated more precisely wherever evidence permits.
A sustained divergence between productivity or output growth and broad-based wage growth would be one indication that existing distributional and political mechanisms may be weakening.
Q3. Markets, finance, and systemic instability
Market mechanisms can coordinate dispersed knowledge remarkably well, but can also generate monopoly, bubbles, correlated risk, algorithmic feedback loops, and crises. AI may intensify both sides. For example, systematically lower costs of goods created by AI may trigger a deflationary descent which undermines many of the basic assumptions of economies around the world.
The challenge is to preserve the extraordinary coordinating benefits of markets while preventing local incentives from generating systemic fragility.
Q4. Media ecosystems and human psychology
Better evidence does not automatically defeat identity, outrage, motivated reasoning, or manipulation. The attention economy may actively undermine epistemic integrity.
Technoprogressive governance must therefore address not only the supply of reliable information but the social and psychological conditions under which people attend to, interpret, and act upon it.
Q5. Democratic legitimacy and expertise
There is no simple formula for balancing equal political standing against unequal knowledge. Different decisions may require different combinations of participation, representation, expertise, delegation, and appeal.
The challenge is not to eliminate this tension but to develop institutions that make the allocation of decision authority explicit, contestable, and appropriate to the kind of question being decided.
Q6. Addressing other trade-offs
Other tensions exist between a number of the above commitments. For example,
- A6 (agency) versus C9 (catastrophic risk)
- A7 (pluralism) versus A3 (protecting vulnerable groups)
- B4 (dissent) versus B1 (disinformation)
- C10 (subsidiarity) versus C9 (global catastrophic risks)
- B7 (calibration before action) versus C3 (renewal before capacity deteriorates)
These tensions should not be papered over or wished away. Instead, whenever they arise, they need to be reviewed with open minds, drawing on multiple perspectives.
Over time, it may become possible to sharpen various commitments in ways that clarify how particular tensions should best be resolved.
Q7. Connecting with existing governance systems
How do existing governance and deliberation systems – whether at local, national, or international levels, and whether hosted by political institutions, NGOs, private entities, or academia – compare to the framework suggested in this article? In which ways are these systems superior and/or inferior to the framework described above?
Similarly, to what extent do existing collaborative information tools align with the principles and processes proposed for a spiral of trust for emerging technologies? In cases of misalignment, how serious are these divergences, and how easily could they be bridged?
Illustrative directions for further work
In response to the issues raised above in “Political economy and entrenched power”, I offer a number of candidate foundations for renewed governance capacity.
I split these into candidate economic foundations (solution ideas S1-S3) and candidate institutional foundations (solution ideas S4-S5).
I do this in the spirit of indicating how solutions might be evolved, via productive dialog, to the various challenges to the technoprogressive governance framework.
I do not presume that any single mechanism – continued mass employment, taxation and transfers, broader capital ownership, public ownership, new forms of collective bargaining, or some combination – will be sufficient. But proposals for future governance will ultimately need to specify which material relationships will sustain public revenue, political standing, and countervailing power.
Candidate mechanisms, such as those listed below, should be compared against the commitments in this article and tested for durability, scalability, legitimacy, capture resistance, and timing.
The common objective of the following candidate approaches is to preserve the material foundations of democratic accountability, including durable stakeholder status, public revenues, and effective countervailing power, despite changing technological and economic conditions.
S1. Broad ownership of productive capital
Examples might include:
- sovereign or social wealth funds;
- citizen ownership funds;
- universal capital endowments;
- public stakes in strategically important AI infrastructure;
- pension funds or collective investment vehicles with broad beneficiaries;
- data or compute dividends tied to ownership rather than discretionary welfare.
S2. Tax-base renewal
Possible approaches include shifting public revenue away from dependence on wage income and towards:
- economic rents;
- capital gains;
- monopoly profits;
- land and natural resources;
- use of scarce compute or infrastructure;
- consumption, where designed progressively;
- public ownership returns.
S3. Predistribution, not only redistribution
This distinction may be especially valuable. Rather than waiting for wealth and power to become concentrated and then transferring some income afterwards, institutions could shape:
- ownership;
- bargaining rights;
- access to infrastructure;
- intellectual-property rules;
- market structure;
- public stakes in innovation;
before the gains accrue.
S4. New forms of countervailing organisation
These might include:
- stronger consumer, citizen, data or technology unions;
- professional associations able to set enforceable standards;
- public-interest compute institutions;
- democratic control over infrastructure bottlenecks;
- international coalitions among states that still retain regulatory and market leverage.
S5. Institutional endowments and protected funding
Independent regulators, research bodies, public-interest media and forecasting institutions could be financed through:
- endowments;
- statutory levies;
- hypothecated revenue;
- multi-year funding settlements;
- diversified funding sources;
- governance protections against donor or industry capture.
Recap
Before deciding who should govern, it is important to clarify the commitments against which any candidate governor ought to be assessed.
We do not need universal agreement on every ethical controversy before we can improve collective decision-making. We need a sufficiently robust initial zone of agreement and practice – a set of principles that diverse people can endorse for different reasons, combined with procedures and behaviours that can begin to earn warranted trust. From that base, we can:
- Build institutions and tools that deserve a limited degree of trust
- Develop the legitimacy, incentives, and leverage needed for those institutions to influence increasingly powerful actors
- Use these institutions and tools to scrutinise more powerful systems
- Where justified by evidence, expand the circle of warranted trust.
The aim is not ever-expanding blind trust. It is ever-expanding warranted, bounded, contestable, and revisable trust.
Trustworthiness depends less on never making mistakes than on detecting, acknowledging, and correcting mistakes rapidly.
In short, trustworthy governance is governance that remains corrigible.
That enables a growing spiral of trustworthy technoprogressive governance.
Endnote: Requesting feedback
Here are some questions where I would particularly value feedback from reviewers:
- Which principle did you most disagree with, and why?
- Which principle surprised you by seeming original or insightful?
- Which principle felt too vague?
- Which principle, if removed, would weaken the framework the least?
- Is there an important commitment that is missing entirely?
- Does the overall structure feel coherent, or merely like a list?
- Do you have any response to the issues raised in the section “Further challenges and open questions”?
Please feel free to answer just one of these questions – or any selection from them.