When Max More writes, it’s always worth paying attention.
His recent article Existential Risk vs. Existential Opportunity: A balanced approach to AI risk is no exception. There’s much in that article that deserves reflection.
Nevertheless, there are three key aspects where I see things differently.
The first is the implication that humanity has just two choices:
- We are intimidated by the prospect of advanced AI going wrong, so we seek to stop the development and deployment of advanced AI
- We appreciate the enormous benefits of advanced AI going right, so we hustle to obtain these benefits as quickly as possible.
From what Max writes, he suggests that an important aspect of winning over the doomsters in camp 1 is to emphasise the wonderful upsides of superintelligent AI.
In that viewpoint, instead of being preoccupied by thoughts of existential risk, we need to emphasise existential opportunity. Things could be a lot better than we have previously imagined, provided we’re not hobbled by doomster pessimism.
However, that binary choice omits the pathway that is actually the most likely to reach the hoped-for benefits of advanced AI. That’s the pathway of responsible development. It’s different from either of the options given earlier.
As an analogy, consider this scenario:

In our journey, we see a wonderful existential opportunity ahead – a lush valley, fertile lands, and gleaming mountain peaks soaring upward to a transcendent realm. But in front of that opportunity is a river of uncertainty, bordered by a swamp of uncertainty, perhaps occupied by hungry predators lurking in shadows.
Are there just two options?
- We are intimidated by the possible dangers ahead, and decide not to travel any further
- We fixate on the gleaming mountain peaks, and rush on regardless, belittling anyone who warns of piranhas, treacherous river currents, alligators, potential mud slides, and so on
Isn’t there a third option? To take the time to gain a better understanding of the lie of the land ahead. Perhaps there’s a spot, to one side, where it will be easier to cross the river. A spot where a stable bridge can be built. Perhaps we could even build a helicopter that can assist us over the strongest currents…
It’s the same with the landscape of our journey towards the sustainable superabundance that could be achieved, with the assistance of advanced AI, provided we act wisely.
That brings me to my second point of divergence with the analysis Max offers. It’s in the assessment of the nature of the risk ahead.
Max lists a number of factors and suggests they must ALL be true, in order for advanced AI to pose an existential risk. That justifies him in multiplying together probabilities, eventually achieving a very small number.
Heck, with such a small number, that river poses no risk worth worrying about!
But on the contrary, it’s not just a single failure scenario that we need to consider. There are multiple ways in which advanced AI can lead to catastrophe – if it is misconfigured, hacked, has design flaws, encounters an environment that its creators didn’t anticipate, interacts in unforeseen ways with other advanced AIs, etc, etc.
Thus it’s not a matter of multiplying probabilities (getting a smaller number each time). It’s a matter of adding probabilities (getting a larger number).
Quoting Rohit Krishnan, Max lists the following criteria, which he says must ALL hold for us to be concerned about AI catastrophe:
- Probability the AI has “real intelligence”
- Probability the AI is “of being “agentic”
- Probability the AI has “ability to act in the world”
- Probability the AI is “uncontrollable”
- Probability the AI is “unique”
- Probability the AI has “alien morality”
- Probability the AI is “self-improving”
- Probability the AI is “deceptive”
That’s a very limited view of future possibilities.
In contrast, in my own writings and presentations, I have outlined four separate families of failure modes. Here’s the simple form of the slide I often use:
And here’s the fully-built version of that slide:
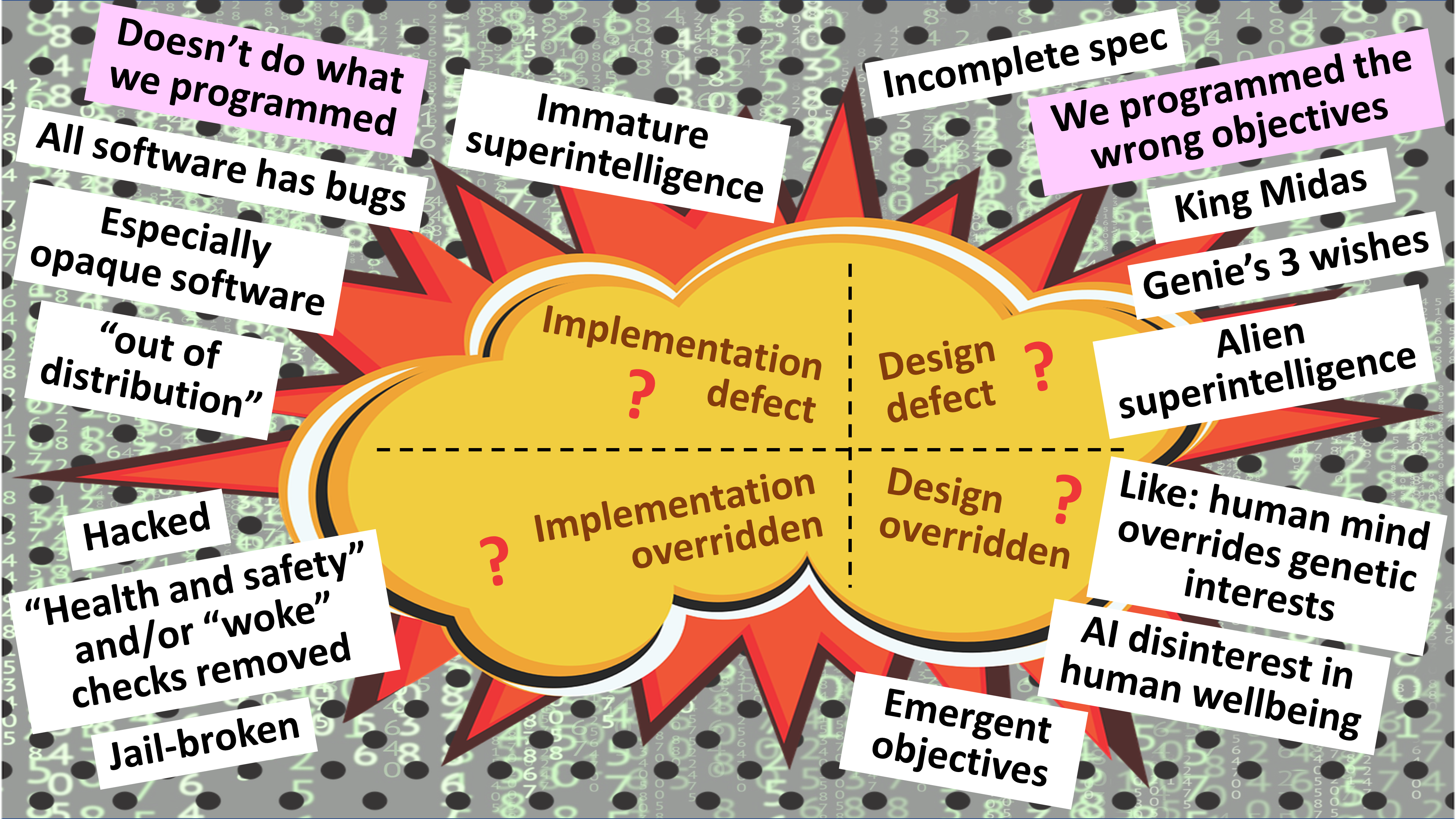
To be clear, the various factors I list on this slide are additive rather than multiplicative.
Also to be clear, I’m definitely not pointing my finger at “bad AI” and saying that it’s AI, by itself, which could lead to our collective demise. Instead, what would cause that outcome would be a combination of adverse developments in two or more of the factors shown in red on this slide:

If you have questions about these slides, you can hear my narrative for them as part of the following video:
If you prefer to read a more careful analysis, I’ll point you at the book I released last year: The Singularity Principles: Anticipating and Managing Cataclysmically Disruptive Technologies.
To recap: those of us who are concerned about the risks of AI-induced catastrophe are, emphatically, not saying any of the following:
- “We should give up on the possibility of existential opportunity”
- “We’re all doomed, unless we stop all development of advanced AI”
- “There’s nothing we could do, to improve the possibility of a wonderful outcome”.
Instead, Singularity Activism sees the possibility of steering the way AI is developed and deployed. That won’t be easy. But there are definitely important steps we can take.
That brings me to the third point where my emphasis differs from Max. Max offers this characterisation of what he calls “precautionary regulation”:
Forbidding trial and error, precautionary regulation reduces learning and reduces the benefits that could have been realized.
Regulations based on the precautionary principle block any innovation until it can be proved safe. Innovations are seen as guilty until proven innocent.
But regulation needn’t be like that. Regulation can, and should, be sensitive to the scale of potential failures. When failures are local – they would just cause “harm” – then there is merit in allowing these errors to occur, and to grow wiser as a result. But when there’s a risk of a global outcome – “ruin” – a different mentality is needed. Namely, the mentality of responsible development and Singularity Activism.
What’s urgently needed, therefore, is:
- Deeper, thoughtful, investigation into the multiple scenarios in which failures of AI have ruinous consequences
- Analysis of previous instances, in various industries, when regulation has been effective, and where it has gone wrong
- A focus on the aspects of the rise of advanced AI for which there are no previous precedents
- A clearer understanding, therefore, of how we can significantly raise the probability of finding a safe way across that river of uncertainty to the gleaming peaks of sustainable superabundance.
On that matter: If you have views on the transition from today’s AI to the much more powerful AI of the near future, I encourage you to take part in this open survey. Round 1 of that survey is still open. I’ll be designing Round 2 shortly, based on the responses received in Round 1.

David, I appreciate your thoughts on my existential opportunity essay. I will respond in sufficient detail when I can. For now, some very brief comments.
On your first point, I dispute the framing of my piece as binary thinking. I am not advocating obtaining the benefits of AI as quickly as possible without any safety measures. I don’t see how you can think otherwise. The last part of my essay lists a range of measures that would slow AI development compared to doing nothing. My approach is to avoid dangerous and damaging regulation. If I were thinking in the binary way you portray, I would call for exemption of AI companies from liability. I do the opposite: “Hold creators and users of AI accountable, using existing liability (including product recall), common law remedies, property and contract law (clarified as needed), and insurance and other accident-compensation mechanisms.”
The Proactionary Principle helps to determine the most reasonable level of cautionary measures and the best institutions and ways to implement them. The principle definitely begins with a presumption favoring freedom to innovate but that is not saying that no one should do anything to be cautious.
On your third point, none of your four closing suggestions are incompatible with my proposals. A longer discussion would be needed to address your point that “regulation needn’t be like that.” One emphasis of my piece was to avoid regulation by a central Department of AI or similar, which is the first thing most people think of. In such a model, regulation is practically always the harmful type that I mention. Nuclear regulation by the NRC in the USA is a classic example. It’s easy to say that regulation need not be a certain way, but the real world has repeatedly demonstrated that you cannot ignore the incentives of agencies and the likelihood of regulatory capture. The work of Gordon Tullock is vital and too little known in this area.
Your second point is the one that prompts me to more reflection. I was uneasy about the multiplicative approach to assessing risk. This may not have come across clearly in the essay but, after explaining that approach, I ended up avoiding it and instead presenting my own list of factors as obstacles to AI disaster, rather than multiplying the elements. I still think this approach is mostly appropriate to assessing the specific risk of AI doom that some voices are loudly proclaiming.
You are entirely correct, of course, that there are other AI risks. For those, my or the other lists of obstacles (whether multiplied or not) are not appropriate. However, I was explicitly addressing the AI doom scenario, not the many other scenarios. If we are considering the full range of possibilities (at least that we can think of), your additive approach makes a lot of sense. So, I’m not sure how much we really disagree. We are talking about different sets of risks. The proactionary approach applies to all AI risks, not just AI doom. However, most (but not all) of my list of sample measures related to the doom scenario, so I can see how you would get the impression that the section on obstacles to AI doom were meant to apply to all AI risks. Thank you for bringing that to my attention. I will clarify that point in blog, when I can find some time.
Comment by Max More — 26 June 2023 @ 6:30 pm