I confess. I’ve been frustrated time and again in recent months.
Why don’t people get it, I wonder to myself. Even smart people don’t get it.
To me, the risks of catastrophe are evident, as AI systems grow ever more powerful.
Today’s AI systems already have wide skills in
- Spying and surveillance
- Classifying and targeting
- Manipulating and deceiving.
Just think what will happen with systems that are even stronger in such capabilities. Imagine these systems interwoven into our military infrastructure, our financial infrastructure, and our social media infrastructure – or given access to mechanisms to engineer virulent new pathogens or to alter our atmosphere. Imagine these systems being operated – or hacked – by people unable to understand all the repercussions of their actions, or by people with horrific malign intent, or by people cutting corners in a frantic race to be “first to market”.
But here’s what I often see in response in public conversation:
- “These risks are too vague”
- “These risks are too abstract”
- “These risks are too fantastic”
- “These risks are just science fiction”
- “These risks aren’t existential – not everyone would die”
- “These risks aren’t certain – therefore we can ignore further discussion of them”
- “These risks have been championed by some people with at least some weird ideas – therefore we can ignore further discussion of them”.
I confess that, in my frustration, I sometimes double down on my attempts to make the forthcoming risks even more evident.
Remember, I say, what happened with Union Carbide (Bhopal disaster), BP (Deepwater Horizon disaster), NASA (Challenger and Columbia shuttle disasters), or Boeing (737 Max disaster). Imagine if the technologies these companies or organisations mishandled to deadly effect had been orders of magnitude more powerful.
Remember, I say, the carnage committed by Al Queda, ISIS, Hamas, Aum Shinrikyo, and by numerous pathetic but skilled mass-shooters. Imagine if these dismal examples of human failures had been able to lay their hands on much more powerful weaponry – by jail-breaking the likes of a GPT-5 out of its safety harness and getting it to provide detailed instructions for a kind of Armageddon.
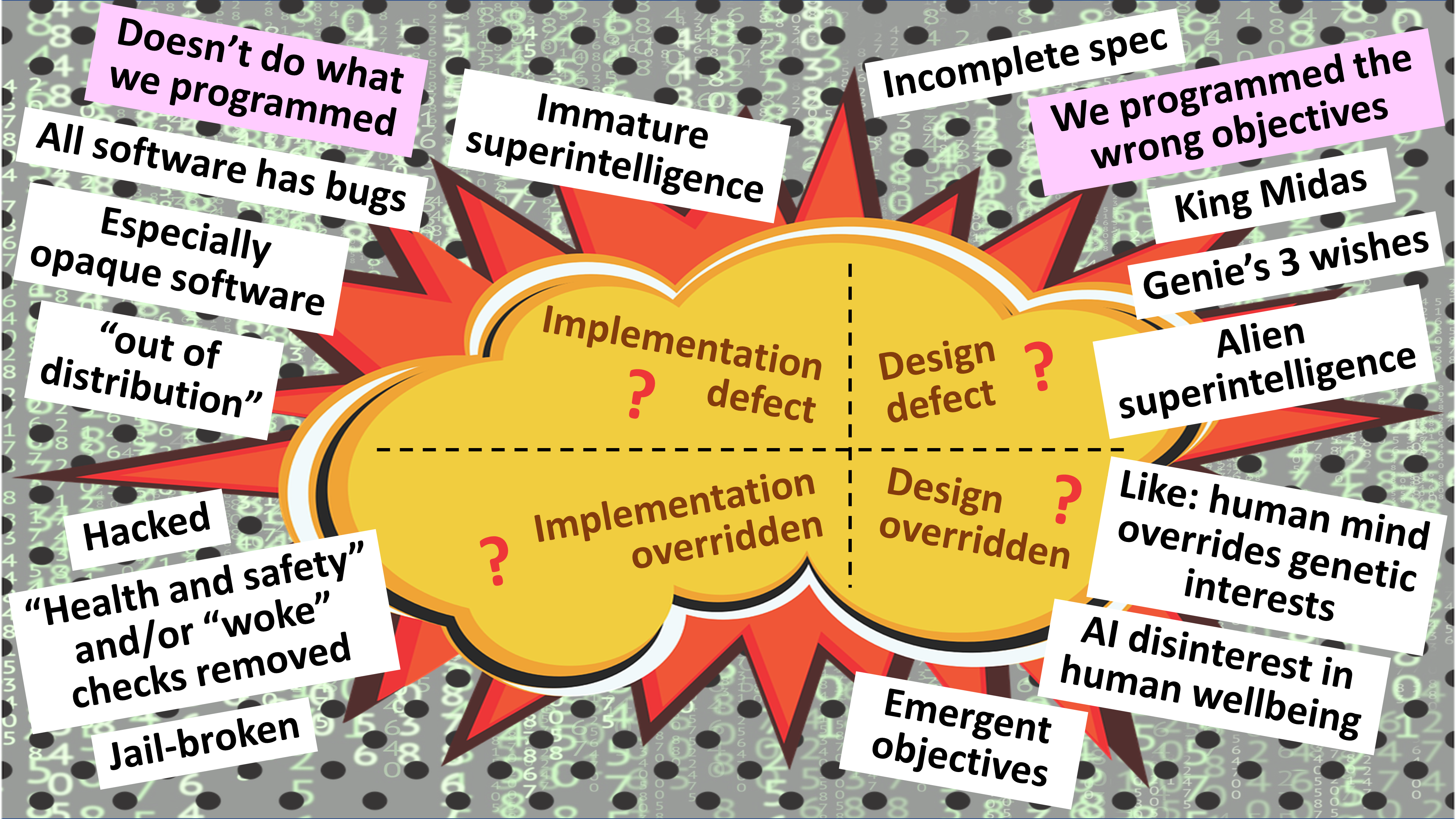
Remember, I say, the numerous examples of AI systems finding short-cut methods to maximise whatever reward function had been assigned to them – methods that subverted and even destroyed the actual goal that the designer of the system had intended to be uplifted. Imagine if similar systems, similarly imperfectly programmed, but much cleverer, had their tentacles intertwined with vital aspects of human civilisational underpinning. Imagine if these systems, via unforeseen processes of emergence, could jail-break themselves out of some of their constraints, and then vigorously implement a sequence of actions that boosted their reward function but left humanity crippled – or even extinct.
But still the replies come: “I’m not convinced. I prefer to be optimistic. I’ve been one of life’s winners so far and I expect to be one of life’s winners in the future. Humans always find a way forward. Accelerate, accelerate, accelerate!”
When conversations are log-jammed in such a way, it’s usually a sign that something else is happening behind the scenes.
Here’s what I think is going on – and how we might unblock that conversation logjam.

Two horns of a dilemma
The set of risks of catastrophe that I’ve described above is only one horn of a truly vexing dilemma. That horn states that there’s an overwhelming case for humanity to intervene in the processes of developing and deploying next generation AI, in order to reduce these risks of catastrophe, and to boost the chances of very positive outcomes resulting.
But the other horn states that any such intervention will be unprecedentedly difficult and even dangerous in its own right. Giving too much power to any central authority will block innovation. Worse, it will enable tyrants. It will turn good politicians into bad politicians, owing to the corrupting effect of absolute power. These new autocrats, with unbridled access to the immense capabilities of AI in surveillance and spying, classification and targeting, and manipulating and deceiving, will usher in an abysmal future for humanity. If there is any superlongevity developed by an AI in these circumstances, it will only be available to the elite.
One horn points to the dangers of unconstrained AI. Another horn points to the dangers of unconstrained human autocrats.
If your instincts, past experiences, and personal guiding worldview predispose you to the second horn, you’ll find the first horn mightily uncomfortable. Therefore you’ll use all your intellect to construct rationales for why the risks of unbridled AI aren’t that bad really.
It’s the same the other way round. People who start with the first horn are often inclined, in the same way, to be optimistic about methods that will manage the risks of AI catastrophe whilst enabling a rich benefit from AI. Regulations can be devised and then upheld, they say, similar to how the world collectively decided to eliminate (via the Montreal Protocol) the use of the CFC chemicals that were causing the growth of the hole in the ozone layer.
In reality, controlling the development and deployment of AI will be orders of magnitude harder that the development and deployment of CFC chemicals. A closer parallel is with the control of the emissions of GHGs (greenhouse gases). The world’s leaders have made pious public statements about moving promptly to carbon net zero, but it’s by no means clear that progress will actually be fast enough to avoid another kind of catastrophe, namely runaway adverse climate change.
If political leaders cannot rein in the emissions of GHGs, how could they rein in dangerous uses of AIs?
It’s that perception of impossibility that leads people to become AI risk deniers.
Pessimism aversion
DeepMind co-founder Mustafa Suleyman, in his recent book The Coming Wave, has a good term for this. Humans are predisposed, he says, to pessimism aversion. If something looks like bad news, and we can’t see a way to fix it, we tend to push it out of our minds. And we’re grateful for any excuse or rationalisation that helps us in our wilful blindness.
It’s like the way society invents all kinds of reasons to accept aging and death. Dulce et decorum est pro patria mori (it is, they insist, “sweet and fitting to die for one’s country”).
The same applies in the debate about accelerating climate change. If you don’t see a good way to intervene to sufficiently reduce the emissions of GHGs, you’ll be inclined to find arguments that climate change isn’t so bad really. (It is, they insist, a pleasure to live in a warmer world. Fewer people will die of cold! Vegetation will flourish in an atmosphere with more CO2!)
But here’s the basis for a solution to the AI safety conversation logjam.
Just as progress in the climate change debate depended on a credible new vision for the economy, progress in the AI safety discussion depends on a credible new vision for politics.
The climate change debate used to get bogged down under the argument that:
- Sources of green energy will be much more expensive that sources of GHG-emitting energy
- Adopting green energy will force people already in poverty into even worse poverty
- Adopting green energy will cause widespread unemployment for people in the coal, oil, and gas industries.
So there were two horns in that dilemma: More GHGs might cause catastrophe by runaway climate change. But fewer GHGs might cause catastrophe by inflated energy prices and reduced employment opportunities.
The solution of that dilemma involved a better understanding of the green economy:
- With innovation and scale, green energy can be just as cheap as GHG-emitting energy
- Switching to green energy can reduce poverty rather than increase poverty
- There are many employment opportunities in the green energy industry.
To be clear, the words “green economy” have no magical power. A great deal of effort and ingenuity needs to be applied to turn that vision into a reality. But more and more people can see that, out of three alternatives, it is the third around which the world should unite its abilities:
- Prepare to try to cope with the potential huge disruptions of climate, if GHG-emissions continue on their present trajectory
- Enforce widespread poverty, and a reduced quality of life, by restricting access to GHG-energy, without enabling low-cost high-quality green replacements
- Design and implement a worldwide green economy, with its support for a forthcoming sustainable superabundance.
Analogous to the green economy: future politics
For the AI safety conversation, what is needed, analogous to the vision of a green economy (at both the national and global levels), is the vision of a future politics (again at both the national and global levels).
It’s my contention that, out of three alternatives, it is (again) the third around which the world should unite its abilities:
- Prepare to try to cope with the potential major catastrophes of next generation AI that is poorly designed, poorly configured, hacked, or otherwise operates beyond human understanding and human control
- Enforce widespread surveillance and control, and a reduced quality of innovation and freedom, by preventing access to potentially very useful technologies, except via routes that concentrate power in deeply dangerous ways
- Design and implement better ways to agree, implement, and audit mutual restrictions, whilst preserving the separation of powers that has been so important to human flourishing in the past.
That third option is one I’ve often proposed in the past, under various names. I wrote an entire book about the subject in 2017 and 2018, called Transcending Politics. I’ve suggested the term “superdemocracy” on many occasions, though with little take-up so far.
But I believe the time for this concept will come. The sooner, the better.
Today, I’m suggesting the simpler name “future politics”:
- Politics that will enable us all to reach a much better future
- Politics that will leave behind many of the aspects of yesterday’s and today’s politics.
What encourages me in this view is the fact that the above-mentioned book by Mustafa Suleyman, The Coming Wave (which I strongly recommend that everyone reads, despite a few disagreements I have with it) essentially makes the same proposal. That is, alongside vital recommendations at a technological level, he also advances, as equally important, vital recommendations at social, cultural, and political levels.
Here’s the best simple summary I’ve found online so far of the ten aspects of the framework that Suleyman recommends in the closing section of his book. This summary is from an an article by AI systems consultant Joe Miller:
- Technical safety: Concrete technical measures to alleviate passible harms and maintain control.
- Audits: A means of ensuring the transparency and accountability of technology
- Choke points: Levers to slow development and buy time for regulators and defensive technologies
- Makers: Ensuring responsible developers build appropriate controls into technology from the start.
- Businesses: Aligning the incentives of the organizations behind technology with its containment
- Government: Supporting governments, allowing them to build technology, regulate technology, and implement mitigation measures
- Alliances: Creating a system of international cooperation to harmonize laws and programs.
- Culture: A culture of sharing learning and failures to quickly disseminate means of addressing them.
- Movements: All of this needs public input at every level, including to put pressure on each component and make it accountable.
- Coherence: All of these steps need to work in harmony.
(Though I’ll note that what Suleyman writes in each of these ten sections of his book goes far beyond what’s captured in any such simple summary.)
An introduction to future politics
I’ll return in later articles (since this one is already long enough) to a more detailed account of what “future politics” can include.
For now, I’ll just offer this short description:
- For any society to thrive and prosper, it needs to find ways to constrain and control potential “cancers” within its midst – companies that are over-powerful, militaries (or sub-militaries), crime mafias, press barons, would-be ruling dynasties, political parties that shun opposition, and, yes, dangerous accumulations of unstable technologies
- Any such society needs to take action from time to time to ensure conformance to restrictions that have been agreed regarding potentially dangerous activities: drunken driving, unsafe transport or disposal of hazardous waste, potential leakage from bio-research labs of highly virulent pathogens, etc
- But the society also needs to be vigilant against the misuse of power by elements of the state (including the police, the military, the judiciary, and political leaders); thus the power of the state to control internal cancers itself needs to be constrained by a power distributed within society: independent media, independent academia, independent judiciary, independent election overseers, independent political parties
- This is the route described as “the narrow corridor” by political scientists Daron Acemoglu and James A. Robinson, as “the narrow path” by Suleyman, and which I considered at some length in the section “Misled by sovereignty” in Chapter 5, “Shortsight”, of my 2021 book Vital Foresight.
- What’s particularly “future” about future politics is the judicious use of technology, including AI, to support and enhance the processes of distributed democracy – including citizens’ assemblies, identifying and uplifting the best ideas (whatever their origin), highlighting where there are issues with the presentation of some material, modelling likely outcomes of policy recommendations, and suggesting new integrations of existing ideas
- Although there’s a narrow path to safety and superabundance, it by no means requires uniformity, but rather depends on the preservation of wide diversity within collectively agreed constraints
- Countries of the world can continue to make their own decisions about leadership succession, local sovereignty, subsidies and incentives, and so on – but (again) within an evolving mutually agreed international framework; violations of these agreements will give rise in due course to economic sanctions or other restrictions
- What makes elements of global cooperation possible, across different political philosophies and systems, is a shared appreciation of catastrophic risks that transcend regional limits – as well as a shared appreciation of the spectacular benefits that can be achieved from developing and deploying new technologies wisely
- None of this will be easy, by any description, but if sufficient resources are applied to creating and improving this “future politics”, then, between the eight billion of us on the planet, we have the wherewithal to succeed!