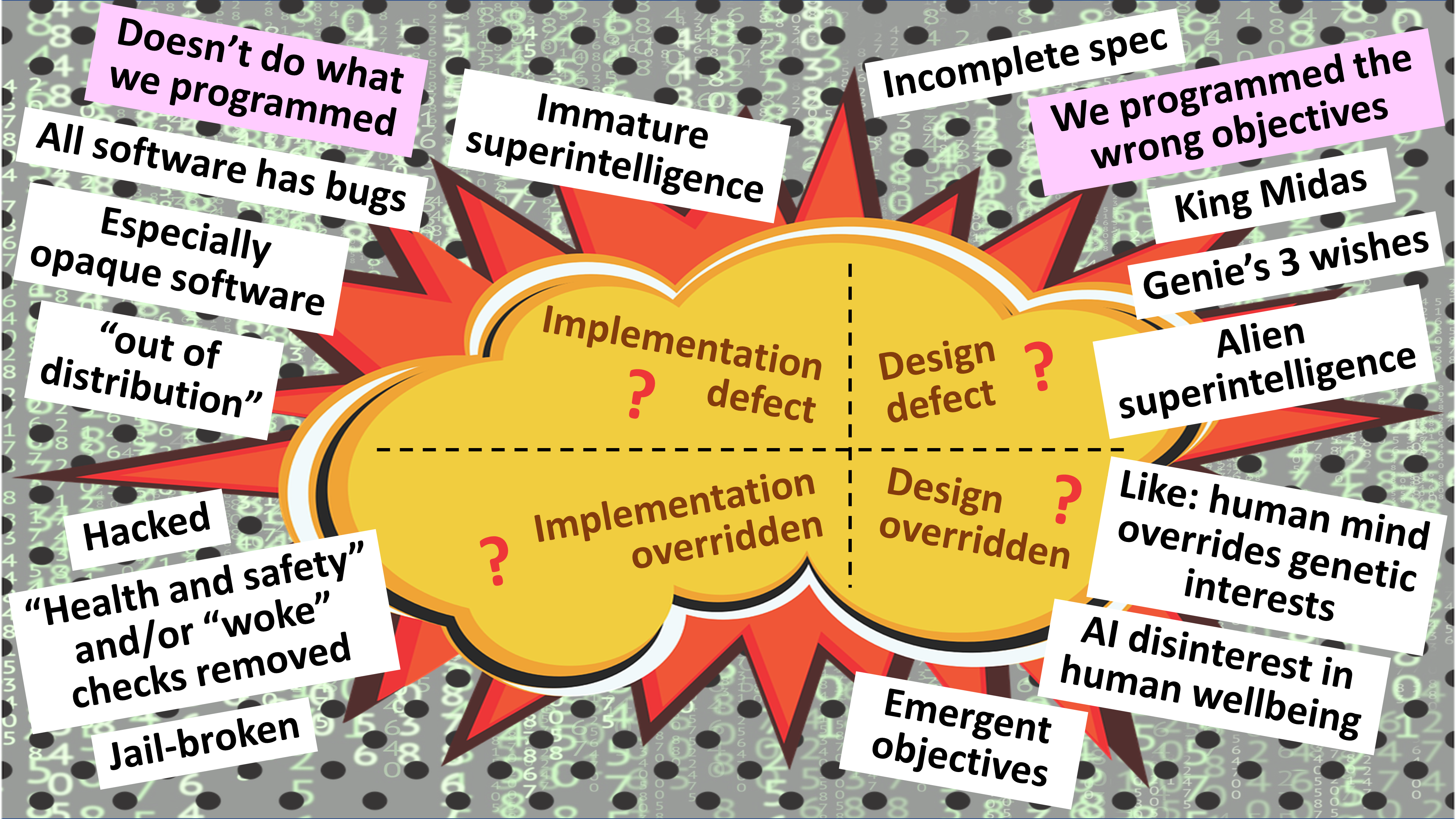
How can we tell when a turbulent situation is about to tip over into a catastrophe?
It’s no surprise that reasonable people can disagree, ahead of time, on the level of risk in a situation. Where some people see metaphorical dragons lurking in the undergrowth, others see only minor bumps on the road ahead.
That disagreement is particularly acute, these days, regarding possible threats posed by AI with ever greater capabilities. Some people see lots of possibilities for things taking a treacherous turn, but others people assess these risks as being exaggerated or easy to handle.
In situations like this, one way to move beyond an unhelpful stand-off is to seek agreement on what would be a canary signal for the risks under discussion.
The term “canary” refers to the caged birds that human miners used to bring with them, as they worked in badly ventilated underground tunnels. Canaries have heightened sensitivity to carbon monoxide and other toxic gases. Shows of distress from these birds alerted many a miner to alter their course quickly, lest they succumb to an otherwise undetectable change in the atmosphere. Becoming engrossed in work without regularly checking the vigour of the canary could prove fatal. As for mining, so also for foresight.
If you’re super-confident about your views of future, you won’t bother checking any canary signals. But that would likely be a big mistake. Indeed, an openness to refutation – a willingness to notice developments that were contrary to your expectation – is a vital aspect of managing contingency, managing risk, and managing opportunity.
Selecting a canary signal is a step towards making your view of the future falsifiable. You may say, in effect: I don’t expect this to happen, but if it does, I’ll need to rethink my opinion.
For that reason, Round 1 of my survey Key open questions about the transition to AGI contains the following question:
(14) Agreement on canary signals?
What signs can be agreed, in advance, as indicating that an AI is about to move catastrophically beyond the control of humans, so that some drastic interventions are urgently needed?
Aside: Well-designed continuous audits should provide early warnings.
Note: Human miners used to carry caged canaries into mines, since the canaries would react more quickly than humans to drops in the air quality.
What answer would you give to that question?
The survey home page contains a selection of comments from people who have already completed the survey. For your convenience, I append them below.
That page also gives you the link where you can enter your own answer to any of the questions where you have a clear opinion.
Postscript
I’m already planning Round 2 of the survey, to be launched some time in July. One candidate for inclusion in that second round will be a different question on canary signals, namely What signs can be agreed, in advance, that would lead to revising downward estimates of the risk of catastrophic outcomes from advanced AI?
Appendix: Selected comments from survey participants so far
“Refusing to respond to commands: I’m sorry Dave. I’m afraid I can’t do that” – William Marshall
“Refusal of commands, taking control of systems outside of scope of project, acting in secret of operators.” – Chris Gledhill
“When AI systems communicate using language or code which we cannot interpret or understand. When states lose overall control of critical national infrastructure.” – Anon
“Power-seeking behaviour, in regards to trying to further control its environment, to achieve outcomes.” – Brian Hunter
“The emergence of behavior that was not planned. There have already been instances of this in LLMs.” – Colin Smith
“Behaviour that cannot be satisfactorily explained. Also, requesting access or control of more systems that are fundamental to modern human life and/or are necessary for the AGI’s continued existence, e.g. semiconductor manufacturing.” – Simon
“There have already been harbingers of this kind of thing in the way algorithms have affected equity markets.” – Jenina Bas
“Hallucinating. ChatGPT is already beyond control it seems.” – Terry Raby
“The first signal might be a severe difficulty to roll back to a previous version of the AI’s core software.” – Tony Czarnecki
“[People seem to change there minds about what counts as surprising] For example Protein folding was heralded as such until large parts of it were solved.” – Josef
“Years ago I thought the Turing test was a good canary signal, but given recent progress that no longer seems likely. The transition is likely to be fast, especially from the perspective of relative outsiders. I’d like to see a list of things, even if I expect there will be no agreement.” – Anon
“Any potential ‘disaster’ will be preceded by wide scale adoption and incremental changes. I sincerely doubt we’ll be able to spot that ‘canary’” – Vid
“Nick Bostrom has proposed a qualitative ‘rate of change of intelligence’ as the ratio of ‘optimization power’ and ‘recalcitrance’ (in his book Superintelligence). Not catastrophic per se, of course, but hinting we are facing a real AGI and we might need to hit the pause button.” – Pasquale
“We already have plenty of non-AI systems running catastrophically beyond the control of humans for which drastic interventions are needed, and plenty of people refuse to recognize they are happening. So we need to solve this general problem. I do not have satisfactory answers how.” – Anon